机器学习-可扩展流形学习方法SUDE
·
一、前置知识
1、 K 近邻集合(KNN)
定义:给定一个点 xix_ixi 与正整数 KKK,它的 K 近邻集合
$$
\mathcal{N}K(i) = \operatorname*{arg,Kmin}{j \neq i} ; d_{ij}
$$
即与 xix_ixi 距离最小的 KKK 个样本的索引集合(实现里通常包含自邻居)
2、反近邻计数(RNN)
定义:一个点 x_u 的 RNN 计数是
$$
\mathrm{RNN}(u)=\left|\left{,i\in{1,\dots,N};\big|; u\in \mathcal{N}_{k_1}(i)\right}\right|
$$
也就是“有多少别人的 KNN 集合把它包含进去”。RNN 能反映枢纽点(hub):在高维/不均匀数据中,某些点会频繁出现在他人的近邻里,RNN 值大。
3、共享近邻(SNN)
核心思想:如果两个点 i,ji,ji,j 的邻居集合高度重合,那么它们“相似”的证据更强。
定义(加权版):设
$$
N_i = \mathcal{N}{k_1}(i)、N_j = \mathcal{N}{k_1}(j)
$$
用 RNN 作为共享邻居的权重,则
$$
\mathrm{SNN}{ij} = \sum{u \in N_i \cap N_j} w(u),
\quad w(u) = \mathrm{RNN}(u)
$$
代码实现:对固定的 i,把每个候选 j 与 i 是否“共享近邻”转成 0/1 指示(np.isin(...).astype(int)),再把被共享的邻居位置用 rnn 加权并对行求和,得到行向量 snn[i,·]。
4、SNN 强度的归一化
为什么要归一化:不同 iii 的 SNN 数值尺度不同(取决于 Ni 的大小/密度/枢纽分布),直接拿来缩放距离不稳。
我们不妨做个测试来验证SNN归一化的必要性:
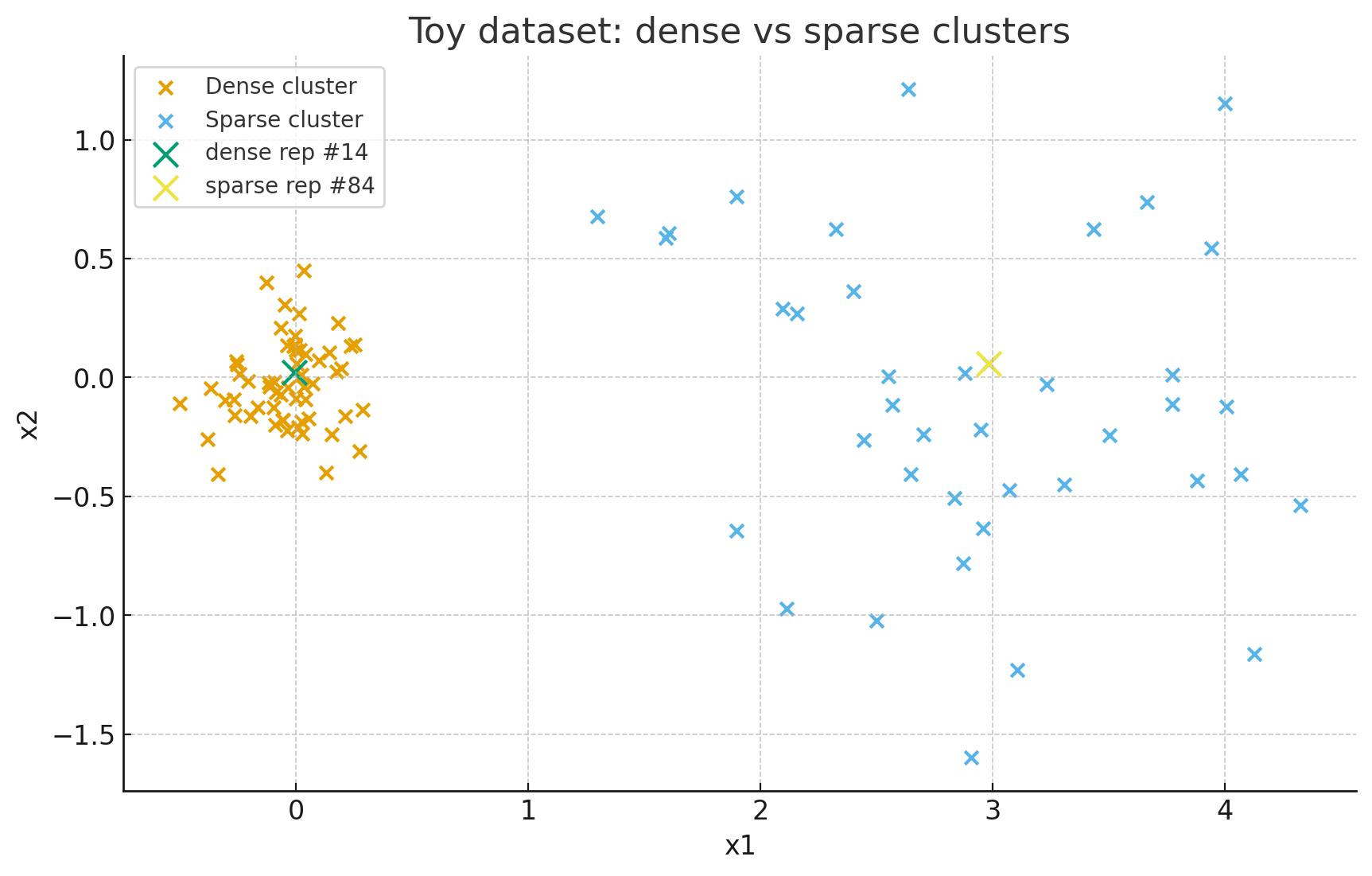
这是原本的散点图(测试数据集)
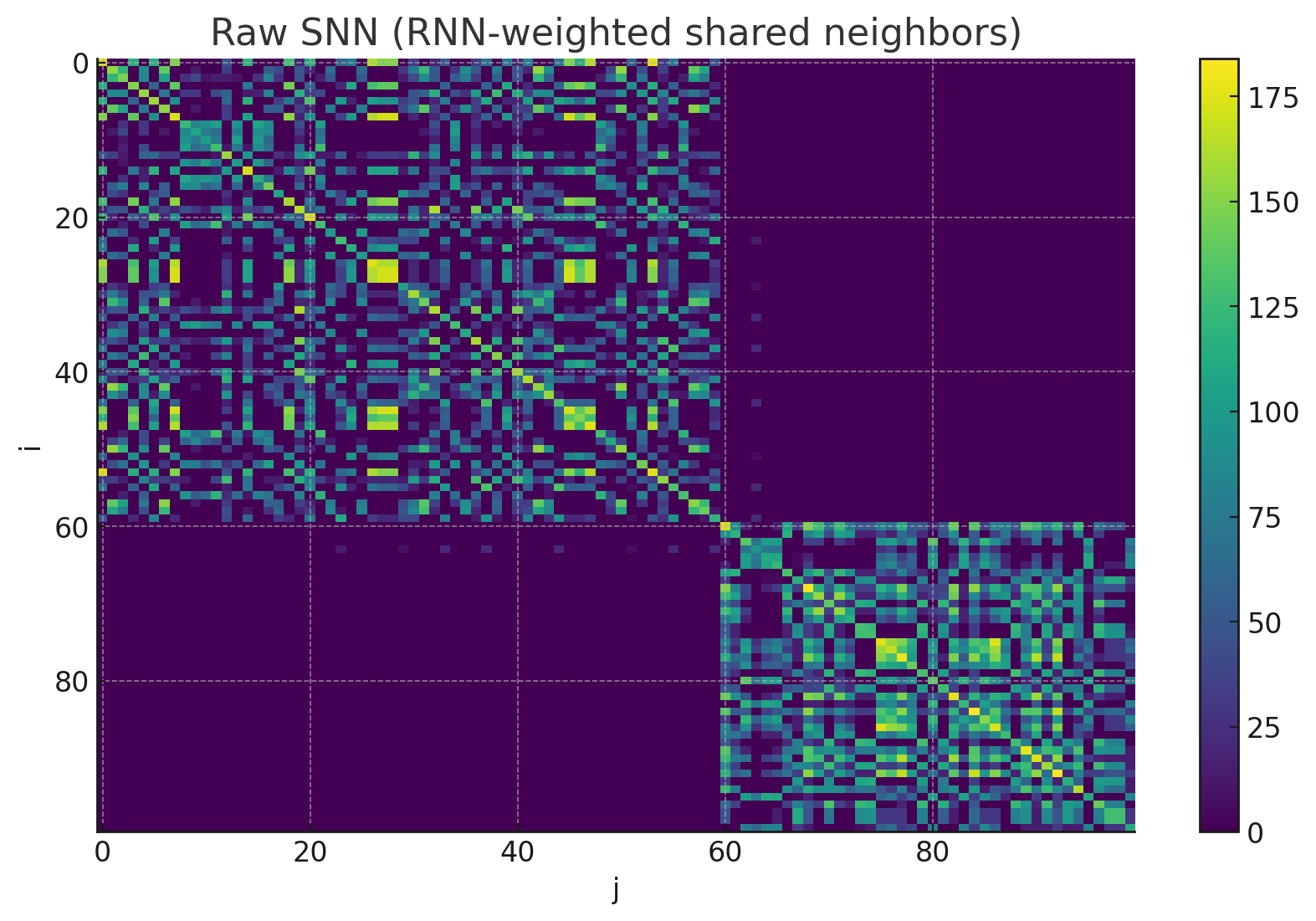
这是未经过归一化处理后的SNN
这是经过归一化处理的SNN
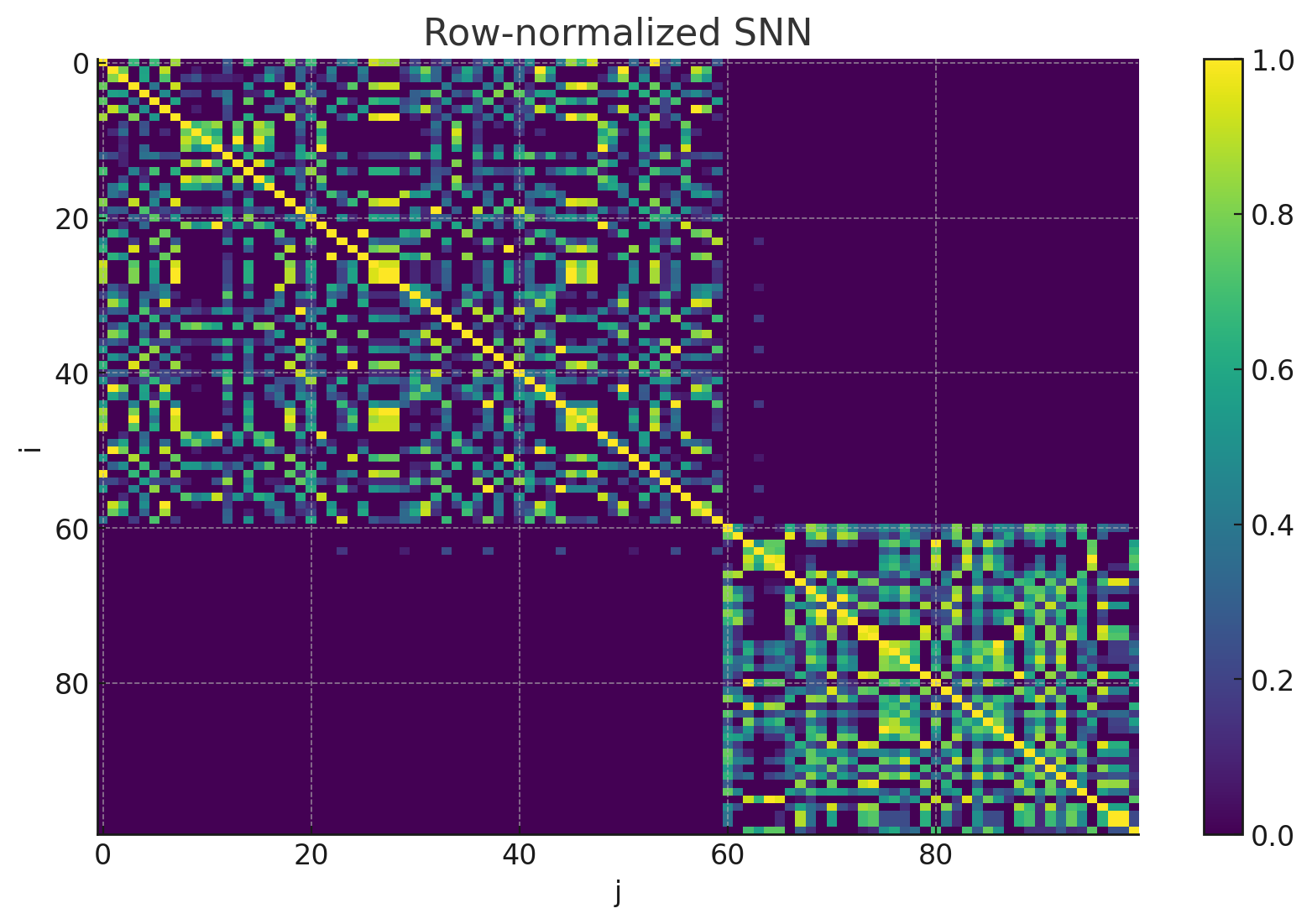
显而易见,归一化处理后不同 i 的数值被压到相同尺度 [0,1],便于后续用来“软缩放”距离。
5、软缩放距离
目的:共享近邻越强(越像同类),就把它们的高维距离乘一个小因子缩短;共享弱的点对则缩放因子接近 1,几乎不变。
定义:给定原始欧氏距离 与归一化后的SNN
$$
d_{ij} 、\tilde{\mathrm{SNN}}{ij}
$$
定义
$$
\tilde{\mathrm{d}}{ij}=(1−\tilde{\mathrm{SNN}}{ij})agg_coef⋅d_{ij},agg_coef>0.
$$
性质:

6、自适应带宽
目的:在密度不均匀的数据上,让每个点有自己的“局部尺度”,避免用全局 σ造成稠密区过拟合/稀疏区欠拟合。
定义:对每个 i,用它经软缩放后的最近 k2个距离的均值当作局部尺度,再平方得到方差:
$$
\sigma_i^2 ;=; \left( \frac{1}{k_2} \sum_{j \in \mathcal{N}{k_2}^{(\mathrm{mod})}(i)} \tilde{d}{ij} \right)^2
$$
在稠密区,σi 小,核变“窄”,只加强很近的点;在稀疏区,σi 大,核“宽”,避免把一切都判为极不相似。
7、高斯核相似度
公式:
$$
P_{ij} ;\propto; \exp!\left(-\tfrac{1}{2}\tfrac{\tilde{d}{ij}^2}{\sigma_i^2}\right),
\qquad j \in \mathcal{N}{k_2}^{(\mathrm{mod})}(i)
$$
其他位置为 0(保持稀疏)。

8、稀疏矩阵的 CSR 表示
概念:CSR 用三组向量存矩阵的非零项:
row:每个非零的行索引(按行块存储)col:每个非零的列索引data:对应的非零值
配合内部指针(indptr)就能重建稀疏矩阵,矩阵–向量乘法/按行切片都很快。
二、算法分析
1、PCA算法:
简介:
PCA 用于大规模或高维数据的降维初始化,目标是:
找方向(主成分):在原始高维数据中,找到一组正交方向,使得数据在这些方向上的方差最大。
投影降维:把原始数据投影到前几个主成分方向上,得到低维表示,同时尽可能保留原始数据的结构信息。
流程:
零均值化:
对每个维度减去均值,让数据中心在原点。
计算协方差矩阵:( 协方差是两个变量的线性相关性强度)
$$
C= \frac{1}{n} X^T X
$$
表示不同特征之间的相关性。
特征分解:
解出协方差矩阵的特征值和特征向量:
- 特征值 λ 表示该方向上的方差大小。
- 特征向量 M 表示该方向的坐标轴(主成分方向)。
排序选取:
将特征值按大小排序,取前 k 个最大特征值对应的特征向量,组成投影矩阵。
投影得到低维表示:
$$
Y=XMk
$$
其中
$$
M_k
$$
是前 k 个主成分向量。
2、PPS算法
简介:
选出一部分点(地标)参与嵌入学习,既能代表整体分布,又不会太密集。优先挑选 “重要点”(RNN 值高 = 在很多人的近邻里出现过 = 数据中心/高密度点)。每选一个地标,就把它周围的点(它的近邻)从候选列表里删掉,避免采样过于拥挤。最终得到的地标,既分散又代表数据核心结构。
流程:
- 排序:按
rnn从大到小排队,形成候选队列id_sort。 - 循环选点:
- 取队首(当前 RNN 最大的点)作为一个地标,加入
id_samp。 - 将这个点的近邻(根据
knn)加入一个待删除集合rm_pts。 - 如果
order > 1,继续扩展,把近邻的近邻也删掉。 - 把这些点从候选队列
id_sort中移除。
- 取队首(当前 RNN 最大的点)作为一个地标,加入
- 重复:直到没有候选点。
- 输出:得到一组分散、密度敏感的地标索引
id_samp。
3、地标上学习低维表示算法
低维:learning_s
流程:输入→建图→初始化→分块优化→输出
高维:learning_l
流程:
三、代码分析
1、PCA算法
1 | |
2、PPS算法
1 | |
learning_l
1 | |